

در سالهای اخیر، مدلهای زبانی بزرگ (LLMها) مانند GPT-4، Gemini و LLaMA 2 شیوهی تعامل ما با فناوری را متحول کردهاند؛ اما این مدلها فقط به دانشی دسترسی دارند که پیش از آموزش به آنها داده شده است. همین باعث میشود پاسخها گاهی قدیمی، ناقص یا نادرست باشند.
برای حل این مشکل، رویکرد RAG (Retrieval-Augmented Generation) معرفی شد؛ مدلی معماریمحور که کمک میکند پاسخهای مدلهای زبانی دقیقتر، بهروزتر و قابلاعتمادتر شوند.
معرفی RAG و تحول آن تا سال ۲۰۲۵
RAG یا تولید افزوده با بازیابی رویکردی است که مدلهای زبانی را با سیستمهای بازیابی اطلاعات ترکیب میکند. بهجای تکیهٔ صرف بر دانش ازپیشآموختهٔ مدل، RAG هنگام پاسخگویی، اطلاعات بهروز و مرتبط را از پایگاه دانش خارجی بازیابی کرده و سپس در تولید پاسخ بهکار میگیرد. نتیجه: کاهش توهم و افزایش دقت و استنادپذیری.
از زمان معرفی، RAG جهشهای مهمی را تجربه کرده است. با انفجار کاربرد چتباتها و نیاز به grounding، RAG به راهحل کلیدی تبدیل شد. ترندهای ۲۰۲۵ شامل پنجرههای کانتکست بزرگتر، ظهور RAG 2.0 (ماژولار و چندمرحلهای: چانکینگ هوشمند، مسیریابی پرسش، ریرنک مبتنی بر شواهد و حلقههای بازخورد) و کاربردهای چندمودلی است. ابزارها/فریمورکهای متنباز ساخت PoC را ساده کردهاند، اما عبور از PoC به Production چالشهای خودش را دارد.
چرا به RAG نیاز داریم؟
مدلهای زبانی بزرگ (LLM) مثل GPT-4، Gemini یا LLaMA با وجود توانایی چشمگیر در تولید متن، دانش محدودی دارند؛ این مدلها فقط به اطلاعاتی متکی هستند که در زمان آموزش به آنها داده شده است. در نتیجه، وقتی از آنها سؤال میپرسیم:
- • نمیتوانند به اطلاعات جدید و بهروز دسترسی پیدا کنند.
- • ممکن است پاسخهای اشتباه یا ساختگی (Hallucination) تولید کنند.
- • توانایی استفاده از دادههای اختصاصی و داخلی سازمان را ندارند.
مشکل کجاست؟
فرض کنید میپرسید: «آخرین تغییرات در قوانین مالیاتی ایران چیست؟» اگر مدل فقط تا سال ۲۰۲۳ آموزش دیده باشد، اطلاعات جدید را ندارد و ممکن است پاسخ نادرست بدهد. یا دربارهی یک محصول خاص شرکت خودتان سؤال کنید؛ چون این اطلاعات در دیتاست عمومی مدل نبوده، هیچ پاسخی ندارد.
اینجاست که RAG وارد میشود
- سیستم RAG ابتدا اطلاعات مرتبط را از منابع واقعی (پایگاه دانش، اسناد داخلی یا وب) جستوجو میکند.
- این دادهها به پرامپت شما اضافه میشود.
- سپس مدل زبانی با ترکیب حافظهی خود و اطلاعات بازیابیشده، پاسخی دقیقتر، واقعیتر و بهروزتر میدهد.
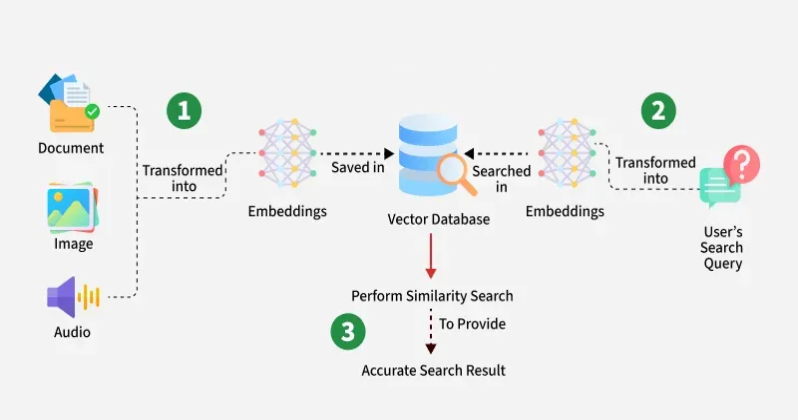
مفاهیم کلیدی در RAG
۱) Embedding (بردارسازی)
تبدیل متن به بردارهای عددی برای جستوجوی معنایی سریع و دقیق.
۲) Chunking (قطعهبندی)
تقسیم متون بزرگ به بخشهای کوچک و معنادار تا با پنجرهٔ زمینهٔ مدل سازگار شود.
۳) Semantic Search (جستوجوی معنایی)
بهجای کلمات کلیدی صرف، جستوجو بر پایهٔ معنا و مفهوم انجام میشود.
کاربردهای RAG در دنیای واقعی
RAG فقط یک مفهوم تئوری نیست؛ در پروژهها و صنایع واقعی بهشکل گسترده استفاده میشود و با اتصال مدلهای زبانی به دادههای واقعی و بهروز، دقت، سرعت و اعتماد کاربران را افزایش میدهد.
۱. پشتیبانی مشتریان و چتباتهای هوشمند
- پاسخدهی سریع و دقیق بر اساس اسناد داخلی و اطلاعات بهروز شرکت
- کاهش نیاز به نیروی انسانی پشتیبانی
- ارائه راهکارهای دقیق، نه پاسخهای کلی
مثال: چتبات پشتیبانی یک شرکت نرمافزاری که به مستندات محصول و تیکتهای قبلی وصل است.
۲. سیستمهای پرسش و پاسخ تخصصی (Q&A)
- پاسخ بر اساس منابع معتبر علمی، حقوقی، پزشکی و …
- مناسب برای سازمانها، دانشگاهها و مراکز پژوهشی
مثال: پاسخگویی هوشمند در یک بیمارستان با استفاده از مقالات و پروتکلهای پزشکی بهروز.
۳. تولید و خلاصهسازی محتوا
- جمعآوری اطلاعات از چند منبع و تولید متن نهایی ساختیافته
- خلاصه کردن مقالات طولانی یا گزارشهای سازمانی
مثال: تولید خودکار خبر بر اساس گزارشهای تحلیلی بازار.
۴. کدنویسی و کمک به توسعهدهندگان
- اتصال به مخازن کد سازمانی برای بازیابی مثالها و الگوهای واقعی
- پیشنهاد کد، تکمیل خودکار یا شناسایی خطاها بر اساس دادههای داخلی
مثال: دستیار برنامهنویسی متصل به مستندات پروژهٔ شرکت شما.
۵. سیستمهای پیشنهاددهنده و تصمیمیار
- تحلیل دادههای کاربر و ارائه پیشنهادهای هوشمندانهتر
- ترکیب اطلاعات لحظهای بازار با رفتار کاربران
مثال: توصیه محصول در فروشگاه آنلاین بر اساس دادههای واقعی.
۶. پژوهش و تحلیل دادههای سازمانی
- جستوجو و بازیابی اطلاعات از انبوه دادههای داخلی
- کمک به تصمیمگیری سریع و مبتنی بر داده
مثال: تحلیل خودکار گزارشهای مالی یا عملکردی برای مدیریت.
مزایای استفاده از RAG
استفاده از RAG یکی از هوشمندانهترین راهها برای افزایش دقت، بهروزرسانی مداوم و قابلاعتماد کردن خروجی مدلهای زبانی است.
| مزیت | توضیح |
|---|---|
| اطلاعات بهروز | اتصال به منابع بیرونی بدون نیاز به آموزش مجدد مدل |
| دقت بالاتر | کاهش خطا و هالوسینیشن |
| صرفهجویی در هزینه | حذف نیاز به آموزش مجدد و پرهزینهٔ مدل |
| امنیت دادهها | استفاده از دادههای داخلی بدون خروج از سازمان |
| افزایش اعتماد کاربر | پاسخهای واقعی و مستند با ذکر منبع |
| توسعه سریع | انعطاف و مقیاسپذیری بالا |
خلاصه چالشهای اصلی RAG
در حالی که RAG (Retrieval-Augmented Generation) مزایای فراوانی دارد و یکی از مؤثرترین روشها برای بهبود عملکرد مدلهای زبانی محسوب میشود، چالشها و محدودیتهایی نیز دارد که اگر در طراحی و پیادهسازی به آنها توجه نشود، کیفیت خروجی و کارایی سیستم کاهش پیدا میکند.
| چالش | توضیح |
|---|---|
| وابستگی به کیفیت داده | دادههای ضعیف = پاسخهای ضعیف |
| تأخیر در پاسخ | بهدلیل مرحلهٔ بازیابی اطلاعات |
| بار پردازشی بالا | نیاز به زیرساخت مناسب جستوجو |
| نگهداری مستمر دادهها | بهروزرسانی مداوم الزامی است |
| عدم شفافیت منبع | کاهش اعتماد در حوزههای حساس |
| انتخاب و رتبهبندی دشوار | تأثیر مستقیم بر کیفیت خروجی |
| زیرساخت پیچیده | نیازمند تخصص فنی بالا |
راهکار کوتاه: کیفیتسنجی داده پیش از ایندکس، کشکردن نتایج/اسناد پرتردد، استفاده از Re-ranker مؤثر، لاگ و مانیتورینگ دقیق، و فرآیند منظم بهروزرسانی پایگاه دانش.
جمعبندی
RAG راهی برای ترکیب قدرت مدلهای زبانی و دادههای واقعی است تا خروجیها قابلاعتماد، مستند و بهروز باشند. چه برای چتبات پشتیبانی، چه تولید محتوا یا سامانههای تصمیمیار، RAG میتواند قلب تپندهٔ نسل بعدی اپلیکیشنهای AI باشد.
نکتهٔ کلیدی: در دنیایی که اطلاعات مدام تغییر میکنند، موفقترین سیستمها آنهایی هستند که به دادههای بیرونی متصلاند— کاری که RAG به بهترین شکل انجام میدهد.
منبع پیشنهادی برای یادگیری بیشتر
اگر به دنبال یادگیری عمیقتر مفاهیم RAG و پیادهسازی آن در پروژههای واقعی هوش مصنوعی هستید، پیشنهاد میکنیم کتاب «RAG-Driven Generative AI» را مطالعه کنید. این کتاب به زبانی ساده و کاربردی، نحوه طراحی معماری RAG، اتصال مدلهای زبانی به پایگاههای داده خارجی، بهینهسازی جستوجوی معنایی و ساخت سامانههای مقیاسپذیر را آموزش میدهد.
این منبع مناسب توسعهدهندگان، پژوهشگران و علاقهمندان به حوزهی هوش مصنوعی است که میخواهند از مرحلهی آشنایی با مفهوم RAG فراتر رفته و آن را در محصولات و راهکارهای عملیاتی پیادهسازی کنند.
