

محققان یک مدل پیشرفته از هوش مصنوعی طراحی کردهاند که میتواند بدون نیاز به راهنمایی یا آموزش مستقیم انسان، صدا و تصویر را در ویدیوها بهصورت خودکار با هم تطبیق دهد. این پیشرفت گام مهمی در ساخت سیستمهایی است که مثل انسان، ارتباط بین شنیدهها و دیدهها را درک میکنند.
برخلاف روشهای قدیمی که نیاز بود انسانها به مدل بگویند «کدام صدا برای کدام تصویر است»، این مدل خودش از روی ویدیو یاد میگیرد که چه اتفاقی در تصویر و صدا رخ میدهد و چطور آنها را با هم هماهنگ کند.
در ادامه این مطلب، بررسی میکنیم این مدل چطور کار میکند، چه ویژگیهایی دارد و چرا میتواند در آینده به رباتها کمک کند مثل انسانها دنیا را بفهمند و به آن واکنش نشان دهند.
هوش مصنوعیای که دنیا را مثل انسان میفهمد: ترکیب صدا و تصویر در یک نگاه
تصور کنید یک کامپیوتر بتواند همزمان صدا را بشنود و تصویر را ببیند—و حتی بداند که این دو به هم مربوطاند. این دقیقاً همان چیزی است که محققان در این پروژه دنبال میکنند: ساخت سیستمی که بتواند مثل انسانها صحنهها را درک کند.
اندرو رودیچنکو، یکی از نویسندگان این پژوهش، میگوید: «ما در حال ساخت سیستمهایی هستیم که مثل انسانها دنیا را پردازش کنند؛ یعنی بتوانند همزمان صدا و تصویر را دریافت و بهطور هماهنگ تحلیل کنند.»
منظور از «تحلیل هماهنگ» این است که سیستم بفهمد صدا و تصویر در یک لحظه خاص از ویدیو به چه چیزی اشاره دارند— برای مثال وقتی تصویر ترن هوایی را میبیند و همزمان صدای جیغ یا حرکت آن را میشنود، متوجه ارتباط بین آنها شود.
این نوع درک چندرسانهای، یعنی توانایی فهمیدن ترکیب صدا و تصویر، قدم بزرگی در هوش مصنوعی است که میتواند در آینده به ساخت رباتهایی منجر شود که با دنیای واقعی طبیعیتر و هوشمندانهتر تعامل میکنند.
هدف: تطبیق هوشمند صدا و تصویر در لحظه، بدون نیاز به دخالت انسان
یکی از چالشهای بزرگ در دنیای هوش مصنوعی این است که بتوان صدا و تصویر را بهصورت کاملاً دقیق و در لحظه با یکدیگر تطبیق داد— بهخصوص بدون آنکه انسان از قبل مشخص کرده باشد که «کدام صدا مربوط به کدام بخش تصویر است».
در این پروژه، محققان سیستمی طراحی کردهاند که میتواند برای هر فریم (تصویر لحظهبهلحظه از ویدیو) دقیقاً صدایی را که در همان لحظه پخش میشود شناسایی کند و آن دو را به هم مرتبط کند. این یعنی مدل میفهمد که، مثلاً، صدای بسته شدن در یا پرواز هواپیما در کجای تصویر اتفاق افتاده است.
نتیجه این کار، مدلی است که میتواند ویدیوها را نه بر اساس عنوان یا توضیح، بلکه صرفاً با استفاده از صدا جستوجو کند— برای مثال وقتی کاربر یک صدای خاص مثل «ترن هوایی» را وارد میکند، مدل ویدیویی را پیدا میکند که آن صدا واقعاً در آن شنیده میشود.
همچنین این مدل قادر است صحنههای صوتی-تصویری را بهطور دقیق دستهبندی کند. صحنه صوتی-تصویری یعنی موقعیتی که در آن، صدا و تصویر همزمان معنا دارند— مثل صدای برخورد توپ با زمین در یک مسابقه یا صدای موتور ماشین در لحظه شتاب گرفتن.
روش کار مدل جدید: درک دقیقتر صدا و تصویر با تقسیم زمان
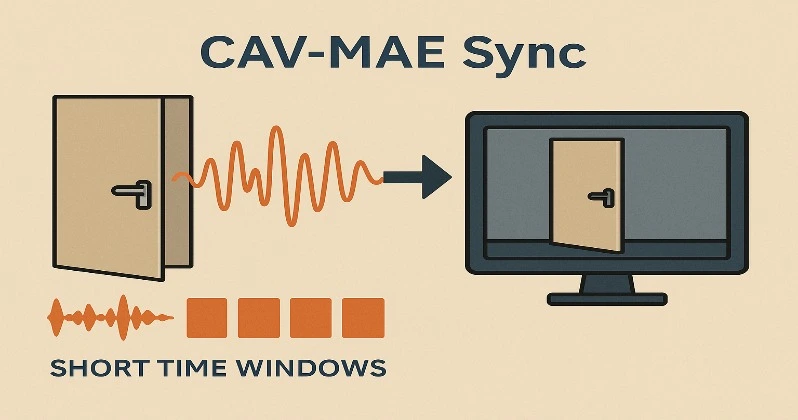
مدل جدید با نام CAV-MAE Sync نسخهای ارتقاءیافته از مدل قبلی به نام CAV-MAE است. در نسخه قبلی، صدا و تصویر بهصورت کلی در نظر گرفته میشدند؛ یعنی اگر در یک ویدیو، مثلاً در بسته میشد و فقط یک ثانیه صدا شنیده میشد، کل ویدیو (مثلاً ۱۰ ثانیه) با آن صدا تطبیق داده میشد—درحالیکه فقط یک لحظه مهم بود.
اما در نسخه جدید، پژوهشگران صدا را به بخشهای زمانی کوچکتر تقسیم کردهاند (که به آنها «پنجرههای زمانی» گفته میشود). این یعنی مدل میتواند برای هر بخش کوتاه از صدا، یک نمای جداگانه بسازد و آن را با همان لحظه از تصویر تطبیق دهد.
در هوش مصنوعی، به این روش میگویند بازنمایی جزئی یا دقیقسازی، یعنی مدل بهجای درک کلی، لحظهبهلحظه یاد میگیرد «چه چیزی دیده میشود» و «چه چیزی شنیده میشود».
این تغییر باعث شده مدل بسیار دقیقتر و هوشمندتر عمل کند و بتواند حتی لحظههای کوتاه و حساس در ویدیوها را بهدرستی تحلیل و طبقهبندی کند.
چطور مدل هم ارتباط بین صدا و تصویر را میفهمد، هم جزئیات را حفظ میکند
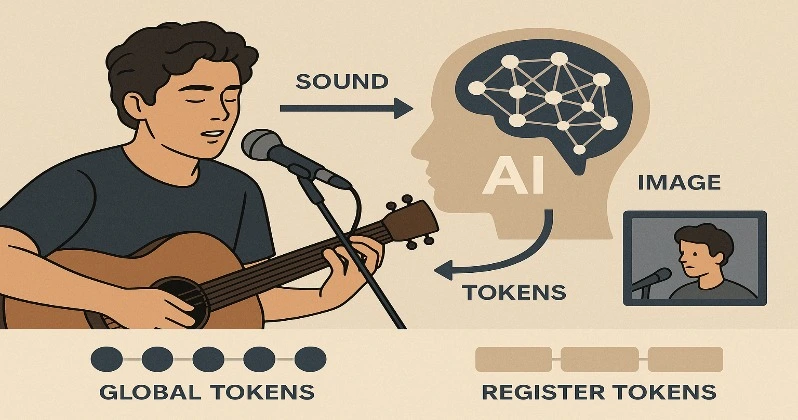
برای اینکه این مدل هوش مصنوعی هم در تشخیص ارتباط بین صدا و تصویر خوب عمل کند و هم بتواند جزئیات دقیق هر صحنه را به خاطر بسپارد، پژوهشگران تغییراتی در ساختار درونی آن اعمال کردهاند.
در واقع، مدل باید هم بفهمد که «این صدا با این تصویر همخوانی دارد» (که به آن یادگیری تضادی گفته میشود)، و هم بتواند اگر کاربر از او خواست، بهدقت بازگو کند که «در آن لحظه دقیقاً چه صدا یا تصویری بوده است» (که به آن یادگیری بازسازی میگویند).
برای رسیدن به این تعادل، دو نوع عنصر هوشمند در مدل طراحی شدهاند که به آنها توکن گفته میشود. توکنها در واقع بخشهایی از اطلاعات هستند که مدل بر اساس آنها یاد میگیرد و تصمیم میگیرد.
نخست، توکنهای کلی (Global Tokens) طراحی شدهاند که به مدل کمک میکنند تشخیص دهد «کدام صدا با کدام تصویر مرتبط است»—یعنی همان بخش یادگیری تضادی.
دوم، توکنهای ثبت (Register Tokens) هستند که به مدل کمک میکنند جزئیات ظریف مثل «چه رنگی؟ چه صدایی؟ چه شکلی؟» را در هر لحظه به خاطر بسپارد— این همان چیزی است که برای بازسازی دقیق دادهها به آن نیاز دارد.
همانطور که اندرو رودیچنکو میگوید: «چون با دادههایی سروکار داریم که هم صدا دارند و هم تصویر (یعنی دادههای چندوجهی)، باید مدلی بسازیم که هم در فهم هرکدام از آنها بهتنهایی قوی باشد و هم بتواند آنها را بهخوبی با هم ترکیب کند.»
نتیجه شگفتانگیز: مدلی سادهتر که بهتر از روشهای پیچیده کار میکند
با وجود اینکه مدلهای زیادی در دنیای هوش مصنوعی وجود دارند که برای آموزش به حجم زیادی از دادهها نیاز دارند، این مدل جدید توانسته با بهینهسازیهای ساده اما هوشمندانه، عملکردی بهتر از بسیاری از آنها داشته باشد.
آزمایشها نشان دادند که این مدل میتواند صحنههایی مانند پارس کردن سگ یا نواختن یک ساز موسیقی را بهدقت تشخیص دهد— آنهم فقط با شنیدن صدا و دیدن تصویر مرتبط، بدون هیچ کمکی از انسان.
ادسون آراوجو، نویسنده اصلی این تحقیق، میگوید: «گاهی وقتها ایدههایی که خیلی ساده به نظر میرسند یا الگوهای کوچکی که در دادهها میبینید، اگر درست استفاده شوند، میتوانند نتایج شگفتانگیزی ایجاد کنند.»
این نتایج نشان میدهد که همیشه نیاز به مدلهای بسیار بزرگ و پیچیده نیست. گاهی با اصلاحات هوشمندانه و دقیق، میتوان به دقت و عملکردی بالا دست یافت—حتی بهتر از روشهایی که منابع و دادههای بیشتری مصرف میکنند.
گام بعدی: ساخت مدلی که همزمان متن، صدا و تصویر را درک میکند
پژوهشگران در تلاشاند تا این مدل را یک قدم جلوتر ببرند: آن را طوری آموزش دهند که نهفقط صدا و تصویر، بلکه متن را نیز درک کند.
این یعنی مدلی بسازند که بتواند همزمان آنچه را که میبیند، میشنود و میخواند، با هم ترکیب و تحلیل کند— درست مثل انسان، که هنگام تماشای یک ویدیو یا مکالمه، صدا، تصویر و کلمات را در یک زمان پردازش میکند.
به این نوع سیستمها، مدلهای زبانی چندوجهی گفته میشود؛ یعنی مدلهایی که هم متن، هم صدا و هم تصویر را درک میکنند و میتوانند بین آنها ارتباط برقرار کنند.
این مسیر میتواند در آینده زمینهساز ساخت ابزارهایی بسیار هوشمندتر برای ترجمه، جستوجو، ساخت ویدیو، آموزش، فیلمسازی و حتی رباتهای تعاملی شود.